Гайд: Как запустить DeepSeek/Llama на MacBook с M4/M5 - пошаговая инструкция

Локальный запуск DeepSeek-R1 или Llama 4 на чипах Apple Silicon M4 и M5 требует минимум 16 ГБ RAM для комфортной работы с квантованными моделями (q4_k_m). Используйте Ollama для быстрой настройки "в одну строку" и платформу MLX для глубокой оптимизации под NPU. Это решение обеспечивает 100% конфиденциальность, но для первичной загрузки весов может потребоваться Три Буквы из-за региональных ограничений репозиториев.
Революция локального ИИ: M4 vs M5
2026 год окончательно закрепил тренд на Edge AI. С выходом iPhone 17 и обновленной линейки MacBook на чипах M5, Apple превратила свои устройства в полноценные станции для инференса нейросетей. Если в 2024-м мы радовались запуску Llama 3 на "минималках", то сегодня DeepSeek-R1 и Llama 4 летают на ноутбуках, выдавая скорость чтения, превышающую человеческую в разы.
Почему M5 - это геймчейнджер?
Ключевое отличие нового поколения M5 от M4 - это внедрение Нейронных Ускорителей (Neural Accelerators) непосредственно в ядра GPU. Это позволяет обрабатывать тензорные операции без постоянной перегонки данных между CPU и Neural Engine, что критично для больших языковых моделей (LLM).
Ключевые факты о железе 2026 года:
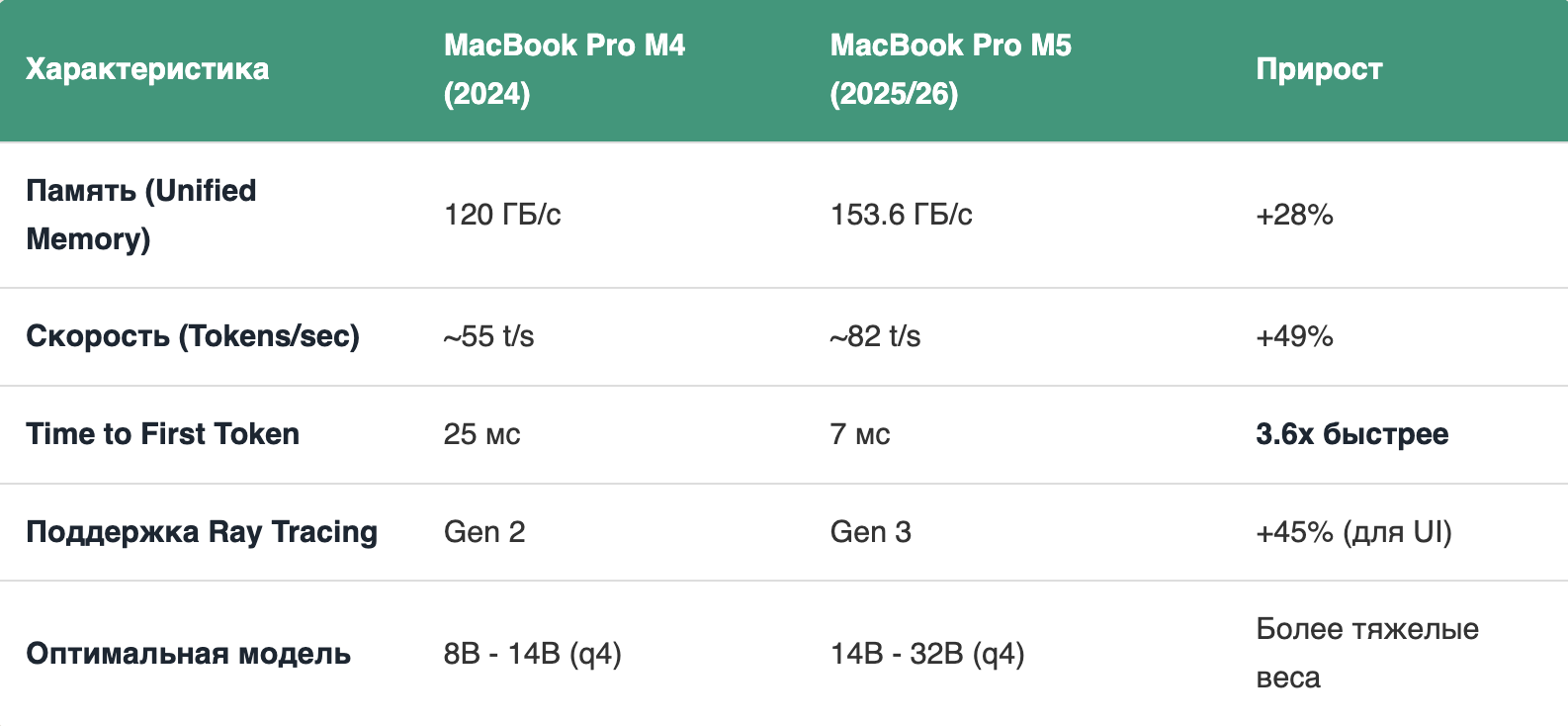
- Пропускная способность памяти (Bandwidth): M5 выдает 153.6 ГБ/с в базе (на 30% выше M4), что напрямую влияет на скорость генерации токенов.
- Кэширование: Второе поколение динамического кэширования (Dynamic Caching) в M5 оптимизирует выделение RAM под KV-кэш модели, позволяя запускать модели 32B на машинах с 36 ГБ памяти без свопа.
- Энергоэффективность: M5 потребляет на 20% меньше энергии при инференсе, чем M4 Pro, что важно для автономной работы.
Таблица: Битва Нейроядер (M4 vs M5)
Ниже приведено сравнение производительности при запуске модели DeepSeek-R1-Distill-Llama-8B (квантование q4_0):
Пошаговая инструкция: Запуск за 5 минут
Для запуска мы будем использовать Ollama - стандарт индустрии в 2026 году для локального запуска LLM. Это проще, чем компилировать llama.cpp вручную.
Шаг 1: Подготовка окружения
Вам понадобится Терминал и пакетный менеджер Homebrew. Если вы разработчик, он у вас уже есть.
Важно: Если официальный сайт Ollama или HuggingFace не открывается, включите Три Буквы. В 2026 году доступ к некоторым репозиториям ИИ может быть ограничен по гео-признаку.
Шаг 2: Выбор и запуск модели
В 2026 году актуальны две ветки моделей:
- DeepSeek-R1: Король логики и кода. Лучшая замена проприетарным моделям OpenAI.
- Llama 4 (8B/70B): Универсальный солдат от Meta*, отлично пишет прозу и поддерживает мультимодальность.
Команда для запуска DeepSeek R1 (версия 8B, оптимальна для M4/M5 Air):
Команда для запуска Llama 4 (версия 14B, для M4 Pro/M5):
(Примечание: Если у вас MacBook с 8 ГБ RAM - используйте модели с тегом :1.5b или :3b, иначе система уйдет в глубокий своп)
Шаг 3: Хардкорная оптимизация (Optional)
Если вы хотите выжать максимум из M5, используйте фреймворк MLX от Apple. Он позволяет загружать слои модели напрямую в Unified Memory без лишних конвертаций.
Мнение Techologi.ru
Мы в редакции считаем, что выход чипа M5 окончательно убил необходимость в платных подписках на "облачные" нейросети для личных нужд.
Инсайт: Главная фишка M5 - это не "сухие" терафлопсы, а именно снижение латентности первого токена (Time to First Token). Для чат-ботов это критически важно: ощущение "живого" диалога возникает именно сейчас, когда задержка упала ниже 10 мс.
Однако будьте реалистами: запускать модель 671B (полный DeepSeek) на ноутбуке все еще невозможно без кластера из Mac Studio. Ваш предел на сегодня - это качественные "дистилляты" размером до 32-40B параметров, при условии, что у вас 48+ ГБ оперативной памяти.
FAQ (Часто задаваемые вопросы)
В: Хватит ли 8 ГБ памяти на MacBook Air M4 для DeepSeek?
О: С трудом. Вы сможете запустить только сильно урезанные версии (1.5B или 3B параметров). Для полноценной модели 7B/8B (уровень GPT-3.5) настоятельно рекомендуется минимум 16 ГБ Unified Memory.
В: Сильно ли греется MacBook при генерации?
О: На чипах M4 - ощутимо, вентиляторы будут слышны. На M5 благодаря улучшенной энергоэффективности и новым нейро-ускорителям нагрев значительно ниже, а на задачах до 7B параметров кулеры могут даже не включаться.
В: Зачем мне локальная модель, если есть веб-версии?
О: Конфиденциальность. Ваши данные не покидают ноутбук. Плюс, это работает без интернета и без необходимости включать Три Буквы каждый раз, когда сервер провайдера "ложится" или блокирует ваш IP.
В: Какую модель выбрать для кодинга в 2026?
О: Однозначно DeepSeek-R1-Distill-Qwen-14B (если позволяет память) или 7B. В тестах HumanEval она опережает базовую Llama 4 на задачах по Python и Rust.
Понравилась статья? Еще больше гайдов и инсайдов из мира технологий в нашем Telegram-канале:
👉 @techologiru
Читайте также

Железная защита: Как включить двухфакторную аутентификацию и перестать бояться взлома 🔒
Пошаговое руководство по настройке двухфакторной аутентификации (2FA) в самых популярных сервисах: Telegram, WhatsApp, Google и Apple ID. Сравниваем методы защиты (СМС, приложения-аутентификаторы, аппаратные ключи) и объясняем, почему код из СМС - это вчерашний день.

Как продлить жизнь аккумулятора смартфона: рабочие настройки и полезные привычки 🔋
Разбираем реальные способы продлить срок службы батареи смартфона. Узнайте, как правильно заряжать телефон, какие настройки отключить для экономии энергии и как мощность зарядки влияет на износ аккумуляторов в дешевых Android и дорогих флагманах.

Keenadu и другие «вирусы из коробки»: чек-лист по безопасности для владельцев Android
Лаборатория Касперского обнаружила новый вирус Keenadu, который заражает Android-смартфоны еще на заводе. На начало 2026 года выявлено более 13 тысяч зараженных новых устройств, большинство из которых - в России. Рассказываем простым языком, как работают вирусы в цепочке поставок, почему обычный сброс настроек не поможет, и даем чек-лист по защите своего смартфона от заводских троянов.